Android Can I Upload a Stream to Aws S3
Streaming Millions of Rows from Postgres to AWS S3
In today's time, requiring reports with millions of rows is a common use case and the same was to exist fulfilled by our in-house ERP Arrangement.
Getting the rows from the Postgres query in one go, iterating over them, creating the CSV file and uploading it to AWS S3.
These are the steps that are generally done for a minor dataset but they neglect miserably when dealing with huge datasets.
How do nosotros bargain with this problem?
Permit'southward beginning with a simple illustration to explain this scenario.
Bob wants to make full a tank located in his backyard with h2o stored in a water tanker. He came up with the beneath approaches:

- In the kickoff arroyo, he gets a storage container having the same size equally required to exist filled and fills it with water from the water tanker. And so, he carries it to fill the tank in the backyard with h2o.
- In the second arroyo, he fills the buckets one by one from the water tanker and then carries them to his lawn to fill the tank.
Also much attempt, isn't it?
- His friend, Alice solves the same trouble by using a pipe to straight transfer water from a tap continued with the h2o tanker till the tank in the lawn. This saved her the effort of filling and carrying the tank or the buckets and didn't tire her for the balance of the mean solar day.
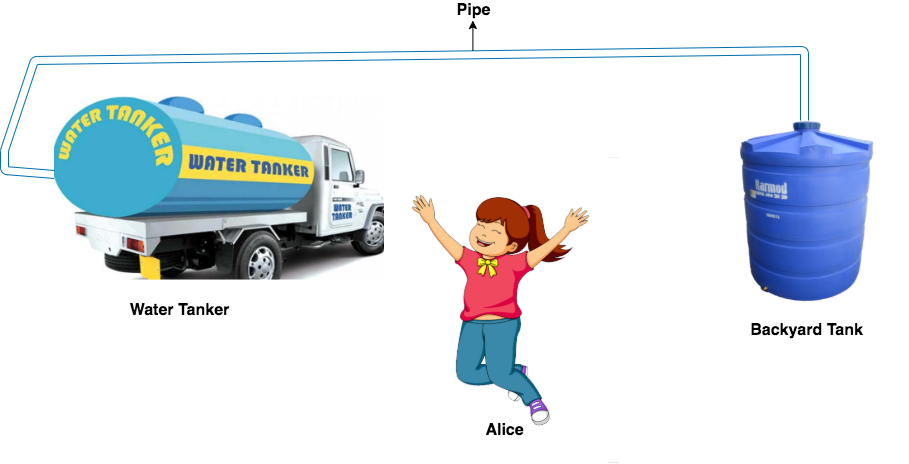
The above scenario can exist compared with how the application pulls data from PostgresDB and uploads to AWS S3. The PostgresDB is equivalent to the Water tanker, AWS S3 is equivalent to the Backyard Tank and the dataset is equivalent to h2o.
The in a higher place 3 approaches will at present be every bit follows:
1. Loading everything at once
A traditional approach where we bring the issue in-retentiveness all at once, prepare a CSV and and then upload to AWS using multipart.
This approach is effective for results containing 100 or m rows but results in an OutOfMemory Exception when the result contains millions of rows.
ii. Using Paging/Slicing
To bargain with the OutOfMemory Exception thrown in the above approach, people mostly utilize the database limit and beginning combination to break the query into smaller queries and read multiple rows in the course of a folio.
In instance of Paging, logic for iteration needs to be written which means more lawmaking to maintain and test. Paging requires an boosted query to calculate the total number of pages in the result. This query can be avoided by using Slicing.
3. Using Streams
The last approach is to pull data from PostgresDB using Jump Data JPA Streams and and so upload to AWS S3 using S3 Streams. This process is called Stream Processing. It means that computation of data is done directly every bit it is produced or received. Streams overcome the disadvantages of both the to a higher place approaches and perform at a fast speed and use less memory footprint.
Permit's look at the steps taken in Stream Processing for creating reports and uploading in AWS S3:
- Streaming data from PostgresDB to Application:
In this step, we are Streaming information while receiving it. For Streaming data from PostgresDB till the Application, we can utilize Spring Data JPA Stream in Java.
In order to make Spring Data JPA stream to work, the render type of the query in the repository file should be Stream<Object>.
@QueryHints(value = {
@QueryHint(proper name = HINT_FETCH_SIZE, value = "600"),
@QueryHint(name = HINT_CACHEABLE, value = "false"),
@QueryHint(proper noun = READ_ONLY, value = "truthful")
})
@Query(value = "SELECT * FROM journal_entries where accounting_entity_id = :accountingEntityId", nativeQuery = true)
Stream<JournalEntry> getJournalEntriesForAccountingEntity(@Param("accountingEntityId") Integer accountingEntityId) Here, the Hibernate has been hinted about the fetch size, the 2d layer caching has been disabled (no caching for the adjacent execution of the same query) and all the loaded objects are read-only.
Things to call back while using Streams:
- Methods using streams must be annotated with @Transactional every bit the connectedness needs to be kept opened so that streams can be consumed.
- Clear the cached data of your object in the EntityManager'southward cache to avoid an increment in cache retention.
- Tweak HINT_FETCH_SIZE and set HINT_CACHEABLE, READ_ONLY according to your use case.
2. Stream processing for CSV Generation:
In this step, we are connecting multiple streams wherein the output of the Postgres Stream becomes input for the Stream uploading the result set in AWS.
@Transactional(readOnly = true)
public String generateReportFileUrl(ReportParam reportParam) throws IOException {
Stream<JournalEntry> journalEntryStream = journalEntryManager.getJournalEntryStreamForAccountingEntity(reportParam.getAccountingEntityId());
return reportExporter.exportToCsv(getReportClass(), journalEntryStream, reportParam.getReportName());
} 3. Streaming data from Awarding to Amazon S3:
In this stride, we are streaming data while producing it. For Streaming data from the Awarding to AWS S3, we can apply the s3-stream-upload library. This library allows efficient streaming of large amounts of data to AWS S3 in Java without the need to shop the whole object in retention or utilise files. This library provides an MultipartOutputStream that packages data written in chunks which are sent in a multipart upload. Later on all the chunks are uploaded, S3 assembles these chunks and creates an object.
POM Dependency for s3-stream-upload library -
<dependency>
<groupId>com.github.alexmojaki</groupId>
<artifactId>s3-stream-upload</artifactId>
<version>2.1.0</version>
</dependency> StreamTransferManager needs to exist initialized with the upload details and outputStream is obtained using getMultiPartOutputStreams(). Along with writing data, the parts are uploaded to S3. Once the procedure of writing data is finished, call MultiPartOutputStream.close(). When all the streams take been closed, telephone call complete().
public <T, U> String exportToCsv(Class<T> reportClass, Stream<U> dataStream, Cord filePath) throws IOException { // Initialize StreamTransferManager and output stream
StreamTransferManager streamTransferManager = new StreamTransferManager(awsS3Bucket, filePath, awsS3Client);
OutputStream outputStream = streamTransferManager.getMultiPartOutputStreams().get(0);// CSV Generator
CsvSchema csvSchema = CsvUtil.buildCsvSchema(reportClass);
CsvMapper csvMapper = new CsvMapper();
CsvGenerator csvGenerator = csvMapper.getFactory().createGenerator(outputStream);
csvGenerator.setSchema(csvSchema);// Processing Stream
dataStream.forEach(information -> {
endeavour {
// writing object to the s3 output stream
csvGenerator.writeObject(data);
} take hold of (IOException e) {
throw new EmsBaseException("Something went wrong :: " + e.getMessage());
}
});// Endmost output stream
outputStream.shut();
streamTransferManager.consummate();awsS3Client.setObjectAcl(awsS3Bucket, filePath, CannedAccessControlList.PublicRead);
URL url = awsS3Client.getUrl(awsS3Bucket, filePath);return url.toString();
}
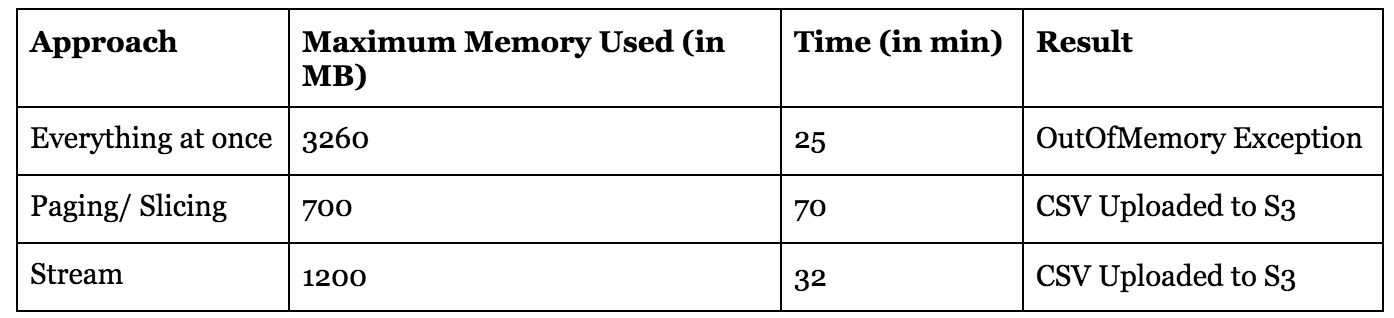
Comparison of the 3 approaches on footing of Memory and Fourth dimension:
For comparison, nosotros accept used a dataset of 1.5 one thousand thousand rows and set the maximum retention limit as 4GB for each test. We accept used JProfiler(Coffee Profiling Tool) to analyse the performance of our approaches.
Determination
Pagination/Slicing is an constructive approach if retentiveness is considered every bit a operation parameter but if we take time as a performance parameter, the time taken in pagination is approximately double that of Streams.
Streams on the other hand, is institute to exist optimal both in terms of retentiveness and time and therefore was our go to approach for creating reports with millions of rows for our ERP Organisation.
References
- s3-stream-upload
- Jump Information JPA — Reference Documentation
- What is Stream Processing? — Ververica
Source: https://tech.oyorooms.com/streaming-millions-of-rows-from-postgres-to-aws-s3-bcfbe859c0e5
0 Response to "Android Can I Upload a Stream to Aws S3"
Post a Comment